
GitHub’s Enfant Terrible: Pull Requests

Considering the fact that GitHub is the world’s largest Git platform. It’s a bit of a mystery how GitHub got away with implementing Pull Requests so poorly
enfant terrible
/ˌɒ̃fɒ̃ tɛˈriːbl(ə)/
noun
a person who behaves in an unconventional
or controversial way.
A Pull Request (PR) is not a core Git concept1, at best it is an interpretation of an original Open Source community collaboration model based on patches. All Git platforms implement their own — slightly different — interpretations of the concept; GitHub, GitLab, BitBucket, Azure DevOps, Launchpad, Gitea, Gerrit …all! But for some reason GitHub’s implementation is still suffering from what could best be categorized as child diseases. But the kid is now in it’s late teenage years. Why isn’t it fixed?
What is a Pull Request good for - originally?
Open source means that the source is open and readable to everyone. But not everyone can write to the source. Only trusted contributors can commit to the Open Source. The contributing workflow design is ancient and predates any existing distributed Version Control System.
The Open Source workflow in a nutshell: If you’re an outsider and want to contribute to the source where you can read, but not write then you must obtain a copy of the source. Since the copy is yours, you can now make changes to the copy. The transfer of these changes between code bases would — back in the days — rely on two standard *nix tools diff and patch. You run diff to create a singel patch file, that contains all the changes you created, in a format that the sibling tool patch would be able to read and apply to the origin.
The patch file would then be attached to a pull request which would either be posted on a mail group, an IRC chat or sent directly as an email attachment to those responsible for the product. They would have write access to the source, and they would then run the patch command. And they would assume ownership and be responsible for releasing the update. Often relying on Semantic Versioning as the contract between the developers of the software and the users of the software.
This flow is still crisp and considered contemporary. Although today’s standard is to use Git features rather than diff and patch.
A flow like this implies:
🤘 Strong Code Ownership - Clear responsibility governed by either benevolent dictatorship (e.g. Linux) or meritocracy (e.g. Apache Software Foundation) means someone who deeply understands the codebase owns every change. No rubber-stamping approvals from random peers.
🤘 Curated Commit History - Linear, pristine main with only shippable commits. No intermediate work cluttering production readiness. It creates a reliable audit trail. Each commit is a valid deployment candidate and can be individually verified and reverted if needed. No merge commits or squash commits obscuring what actually changed.
🤘 One Issue equals One Commit - Atomic changes are easier to understand, test, and reason about. The VCS history itself reads like documentations. All changes are there for a specific reason. Reduces cognitive load during code review and debugging.
🤘 Explicit Preparation Phase - The ritual of creating a single packaged (then: a patch file, today: a single commit) containing all changes before submission forces developers to clean up their work, run all tests and verifications, understand and argue their changes, and to document and present them coherently.
🤘 Graduated Responsibility - New contributors earn write access through demonstrated competence, merits are the foundation of trust. This scales better than trying to peer-review everything from day one.
🤘 Semantic Versioning as a Clear Contract — Users and downstream consumers get a reliable upgrade signal; Semantic Versioning is the foundation for dependency resolution among individually releasable components. QA passes, release notes and advisories become simpler and less noisy. Overall this reduces regressions and encourages conservative, documented evolution rather than implicit, and arbitrary ad‑hoc changes.
We should work internally — even on our own proprietary code — as if we were contributing to Open Source
When I argue this to my teams it is specifically these virtues listed above that we aim for. The quality should be applied at the source; the developer’s workspace - not glued on as an afterthought. We should not rely on peers doing arbitrary and mostly opinionated reviews. But rather on those responsible obtaining actual ownership. Each individually releasable component has an undisputed owner. In our team we call this person the Module Key Responsible (MKR). It’s a role I was first introduced to at Ericsson Communication Systems 25 years ago.
Git for the win!
However, this workflow is very labor intense when it’s based on diff and patch in completely detached source repositories, especially for more complex code bases. Tool support is definitely needed for assessing changes in context, rather than in patch files, for supporting the back-and-forth process of feed-back and resolving merge conflicts.
Linus Torvalds is the champ in this area, right from the start of the Linux kernel the community relied on a Distributed Version Control System (DVCS). The standard tools of that time; PVCS, CVS, Subversion etc. were all discarded as inferior. Instead the Linux Kernel project used BitKeeper. Supposedly the world’s first DVCS. But the story goes, that Linus ended up in a controversy with the makers of BitKeeper over allegation of the community trying to backward engineering the internals of the tool. So to avoid the conflict Linus started hacking on Git2.
Plural, there were more than one contender: Mercury, Bazar, Git all has a historical off-set in Linus’ quest for a new home grown, Open Source Distributed Version Control System to replace BitKeeper.
That battle has ended. Even Canonical’s (home of the Ubuntu distro) LaunchPad, which was build as a platform on top of their own DVCS Bazar is now definitively sun-setting Bazar in favor of Git.
The equivalent Open Source Contribution flow in Git is deliciously simple :
- Create a fork - this is easy, since the Version Control System is distributed by nature. Repository copies do not appear as detached, but rather connected. Now you (and your colleagues) have write access to a copy, which is version controlled too.
- Make you desired changes in your own fork and commit them to a dedicated branch — This is the equivalent of the
patch. - Since you still can not write (push) to the original repo, what you do instead is that you give those responsible for the product access to your repo and ask them to pull the branch and merge if from your fork repo to their
main. - Due to the distributed nature of git, the internal workings of the heuristic diff algorithm, the direct acyclic graph architecture and the fascinatingly light-weight implementation of the branch concept. Any two branches/commits can easily be merged.
The Linux kernel community used this optimized flow already in BitKeeper. Once you left the work intense diff and patch workflow there was no going back.
So to summarize on the Pull Request concept in Git; technically there is no actual pull request implemented in git, it’s more like a nick name for the Open Source contribution process flow.
What is a Pull Request good for - in GitHub?
In GitHub a Pull Request is essentially an attempt to implement some tool support around the Open Source contribution model described above. But I would claim that many PR implementations miss out on many of the desired outcomes in the process. And GitHub’s Pull Request is no exception.
Although GitHub’s PR do support working with forks too, as described above I’ve seen close to 100% of all PR implementations in proprietary GitHub repos works within the same repo. Often with a ruleset or policy around it, that makes it behave almost like a fork:
- You don’t have write access to
main - Peer reviews and manual approvals are required before the PR is merged in
- Tests and statuses (often automated in declarative workflows) are required
But there is no requirement or even encouragement that the branch history on main should be linear and pristine. In fact the merge strategies offered are more harmful than helpful - I’ll get back to that in a bit.
Under the hood; In essence a Pull Request in GitHub is implemented as a variant of a Github Issue.
Note that these features are not Git native, they are implemented on the individual Platform, GitHub, GitLab, Bitbucket Azure DevOps etc. So you submit to a certain flavor and in reality also to a vendor lock in. Moving your repos to another platform would require transforming to — and sucking up — a new flavor.
So how do we like the GitHub flavor of Pull Requests?
Well, ‘PR’ is generally recognized as an abbreviation of Pull Request. But specifically in GitHub’s flavor of the implementation it would probably be just as relevant to see it as an abbreviation of Peer Review. The entire Pull Request process is designed around the assumed need for code reviews.
But is that at good approach?
What If…
- We believe task switching is evil, it greatly increases the cognitive load. Being asked to stop an ongoing process, switch to review another and then go back to the first is indeed task switching.
- We believe that hand-overs create wait states – on top of the increased cognitive load, it quite literally adds idle time to the Value Stream simply. This idle time adds to the overall Change Lead Time, which is the first of the DORA metrics
- We are committed to paired programming or even mob programming. While we do indeed adhere the four-eye-principle we claim that it should be covered through how we organize the work process, not as a quality gate.
- We run extensive automated verifications; static code analysis (linting, cyclomatic complexity, spell checks), unit tests, fuzzy tests, we build, deploy and run our E2E regressions tests in a production-like environment before we try to hit
main. - We keep
mainpristine and always shippable and we adhere to Continuous Delivery. Even if bad code style or even failures should have passed through our automated verification, we believe that optimizing our Deployment Frequency (the second DORA metric) and our Failed Deployment Recovery Time (the fourth DORA metric) - is short picking up speed, is a better approach that adding self-inflicted, manual wait-states. - Our Change Failure Rate is low (the third DORA metric) and also the Rework Rate (the fifth DORA metric - newly added in ‘24) is low too — nothing indicates that our process produces poor quality.
In our situation, where all this is true — without enforcing Peer Reviews — the GitHub Pull Request’s implication of stop-go wait states and task switching would only inflict pain.
Our principles
The results mentioned above are gained from designing our own ideal development principles. Inspired by the Open Source Contribution workflow. They read like this:
- We work with a kanban approach. We describe our GitHub issues so that each match a commit onto main — one issue becomes one commit. Work logs, audit trails, design considerations are posted on the issues.
- We attach a dedicated development (very) short-lived branch to each issue.
- We keep our work-log, comments and design decisions in our issues.
- We require our history on
mainto be strictly linear and we only allow merges onto main that can befast-forward, this ensures, that the commit that is verified in the process is the exact same (same SHA) as the one that ends up onmain. - We keep
mainpristine – all commits onmainare potentially shippable no intermediate commits are allowed.mainis the only long-lived branch we have. - A branch that is to be delivered to
maincan only contain one commit. This implies that contributors must always prepare their branch and make it ready for delivery; sync tomain, collapse and run all verification steps to produce only a single commit that can be fast-forwarded. This is done by the contributors themselves, in their own workspace. - We do not consistently require a peer review on our code before it’s merged to
main, instead we run extensive automated tests and static code analysis in our workflows which sets various commit statuses which must all be successful for the development branch to be deliverable ontomain. - We do adhere to the four-eyes principle. But we do this as part of the development process, not as an opinionated peer review used as a quality gate.
- We adhere to individually releasable components as opposed to a mono-repo. The composite product structure and dependency map is automatically maintained in a deployment manifest.
- Releases are based on strict compliance with SemVer 2.0. Deploys are automated, release note generation is automated.
So — that’s the process we believe in and which has proved impressively efficient.
Since we were working in GitHub our first attempt to build tooling around this process was to utilize the standard GitHub features, including Pull requests. But several issues emerged, that led us to design and build our own tool support. Based on a few GitHub Cli extensions and a small repo of dedicated generic callable workflows.
These tools are all open source and available for free for everyone who would like to walk the same path as us. I’ll summarize them briefly in the following – I plan to dive into further detail in future blog post. But first let me finish my rant against the gitHub Pull Request and why we discarded it all together.
So what’s the problem - in GitHub?
⚠️ The issues are eclipsed by the pull request
When we work extensively with issues, we’d like the comments related to the code developed in contest of that issue, but a GitHub Pull Request is under the hood implemented as a specialized variant of a GitHub Issue - so when using the Pull Requests we get another issue on top of the original issue, so now we have two logically identical issues - they both relate to the same development branch. It’s a mess. we want comments, design decisions and work logs and audit trails in context of the original issue. It felt like GitHub Pull Request were nothing but intrusive party crashers.
⚠️ Pull Requests don’t support true linear (fast-forward) history
It’s a git technical, somewhat nerdy, discussion, but it’s well covered in this Feature request discussion on GitHub.
Supporting a true linear history is so fundamental in Configuration Management for build avoidance, optimization by cache utilization and in compliancy in general. Like most others in this thread we couldn’t believe our own findings and conclusions when we learned, that none of the three available merge strategies in GitHubs’s Pull Requests (merge,rebase,squash) are capable of supporting a fast-forward merge. Not even if we carefully prepared it, and verified that a fast-forward merge was indeed possible.
😱👎 The Pull Request will always create a new commit. Never fast-forward the one presented to it.
This discovery was as unacceptable as it was shocking. GitHub PR’s are ruining and ignoring some of the most desirable features built into Git itself.
Workon, Wrapup, Deliver
We took the decision to create our own tool. It’s build as an extension to the GitHub CLI gh. The GitHub CLI come with a built-in package manager so the installation is easy. It’s literally a one-liner, gh extension install very similar to apt-get install or npm install
Our GitHub CLI extension provides a small handful of sub commands at the core are workon, wrapup and deliver. We created short-hand aliases in our setup (devcontainer) so that they appear as native first-class citizens to the gh tool.
workon
This command will set up a new branch for a specific issue, unless a branch for that issue already exits, then it will reuse that. It also supports an option to create a new issue on the fly and work on that.
This is the foundation of our collaboration model, if more developers run the same command, they will get the same branch. So this is also fundamental for how we support paired programming in a distributed team.
# This will create a new - or reuse and existing
# development branch on issue 32
gh workon --issue 32
wrapup
This command is used to commit and push the current state of the workspace to origin. I you haven’t added anything to Git it will default to add all changes (git add -A) but if you have already explicitly added something then it will just go with that.
The command takes just one parameter; the base of the commit message. The actual commit message will be suffixed with a reference to the issue it relates to, this way all individual commits will be mentioned in the issue and compile a full trace. This is a GitHub feature that we’re just exploiting. So we get that audit trail for free simply by referencing the issue in the commit message.
Developers are free to make as many commits on the issue-branch as they want, in fact we encourage them to use wrapup frequently when they go to lunch, share current work with a colleague (👀👀-principle), I often use it myself just to commit my dirty files and come clean before I run another AI prompt in agent mode, because I find that Git is far better at keeping track of changes than the AI agent is.
# wrapup as often as you want and for no specific reason
gh wrapup "I´m off to lunch"
gh wrapup "I think that was that"
gh wapup "dotted the i´s and crossed the t´s"
In order to support the 👀👀-principle, We have enhanced GitHub Pull Request’s CODEOWNERS concepts and created a variant of it called REPONSIBLES. It’s a file you put in the root of the repo which use standard git glob syntax (as opposed to CODEOWNERS which uses an homegrown syntax) to list those responsible for different files in the repo. wrapup reads the RESPONSIBLES file and unless the current user is listed as responsible herself, the change set is listed as a comment on the issue together with a mention of those responsible. It’s a standard build-in feature in GitHub that if you mention someone in an issue comment, they will automatically get a notification from GitHub. The responsible can then take a peak and see if all is on track and react if necessary.
We have a dedicated workflow wrapup.yml which triggers on all issue branches, which by design always start with an integer; the issue number:
on:
push:
branches:
- '[0-9]*'
It runs all our static analysis, linting and unit tests and each individual verification sets the status on the commit utilizing GitHubs commit statuses feature. At this point it’s not a strict quality gate, it’s more like a service to the developer.
This is the situation up till now:
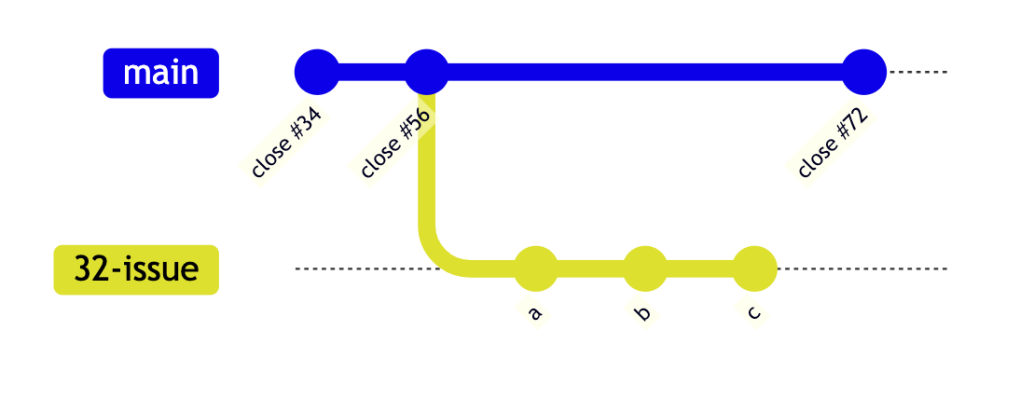 I've started working on issue 32. I did three commits with 'wrapup', now I'm done and I'd like to deliver to main but in the meantime main is updated with stuff I haven't seen on my branch yet.
I've started working on issue 32. I did three commits with 'wrapup', now I'm done and I'd like to deliver to main but in the meantime main is updated with stuff I haven't seen on my branch yet.non-compliant: In this state I can not deliver; since my branch isn’t in sync with mainthe merge wouldn’t be fast-forward and also my branch contains more than one commit, so even If did sync to main my intermediate commits a and b commits would void the pristine-ness. of main.
First thing we need is to sync with main to enable a fast-forward merge:
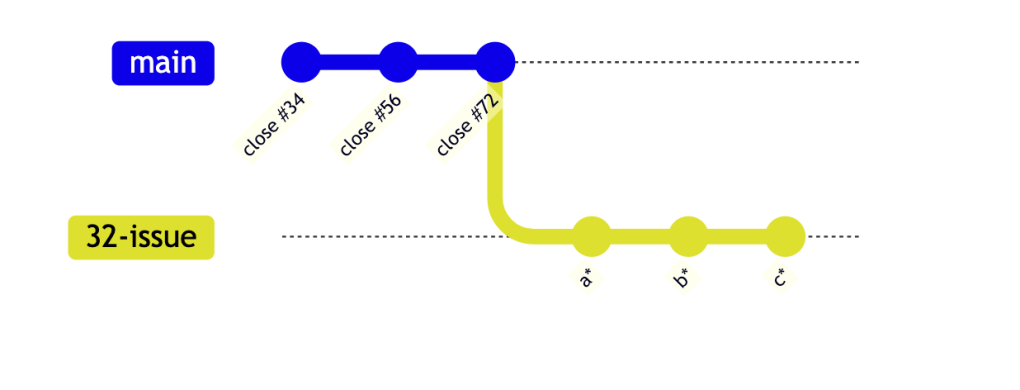 I run a rebase to sync to main. Technically this will rewrite history - my a, b and c commits will be given new SHAs but at this point – on my own dev branch – I don't care about the SHAs. They are not important — yet. If they were I could obtain the same result with a merge commit from main onto the issue branch. That would create a merge commit, which I don't want on my main, but which I also don't care about on my own issue branch. So developers are free to do what they want, as long as they get in sync with main and enable a fast forward merge.
I run a rebase to sync to main. Technically this will rewrite history - my a, b and c commits will be given new SHAs but at this point – on my own dev branch – I don't care about the SHAs. They are not important — yet. If they were I could obtain the same result with a merge commit from main onto the issue branch. That would create a merge commit, which I don't want on my main, but which I also don't care about on my own issue branch. So developers are free to do what they want, as long as they get in sync with main and enable a fast forward merge.deliver
The deliver command takes no parameters, everything needed to perform the deliver can be derived from the context. It will check for fast-forward-ness and abort is it’s not possible. It will also summarize the entire history of the issue branch in the commit message, so that even if we’re about to soon delete the issue branch the history remains retrievable on the GitHub issue.
# Squeeze the issue branch into just one commit
# Put it on a dedicated ready branch and push that
gh deliver
The result from this is:
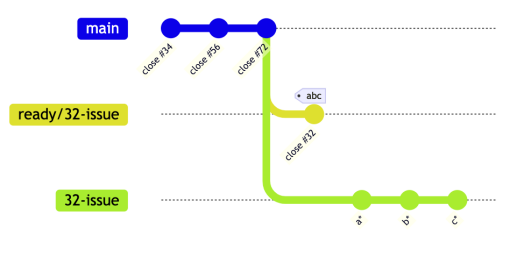 At this point, if a run a diff on 32-issue and ready/32-issue they are 100% identical - The process is conceptually the same as a squash merge only it doesn't happen in the merge process. But in a separate commit on a separate branch, where it can be scrutinized and verified before the merge.
At this point, if a run a diff on 32-issue and ready/32-issue they are 100% identical - The process is conceptually the same as a squash merge only it doesn't happen in the merge process. But in a separate commit on a separate branch, where it can be scrutinized and verified before the merge.Under the hood, the ready branch is created with a git commands similar to this (they are slightly simplified for readability)
# Creates and capture the 'squashed' commit from the tip of the issue branch
READY_COMMIT=`git commit-tree 32-issue^{tree} -p main -m "close #32"`
# Push it to origin, the ready branch isn't even created locally
git push origin $READY_COMMIT:ready/32-issue
The ready verification flow now runs on the ready/32-issue branch it will start by inherting all the commit statuses set on the tip of the issue branch. They must all be successful. Then it will run any additionl verifications and set the commit statuses for the outcome of each. If all goes well it will fast-forward the ready branch onto `main, close the issue, and purge both the ready branch and the issue branch. The (very) detailed audit trail is stored as commit statutes on the commit in GitHub.
The result will be:
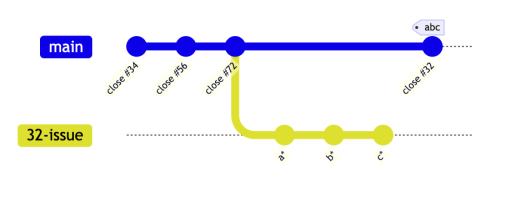 In a 'fast-forward' merge no new commit is created in the process, the main HEAD is simply moved to the existing SHA1. Keeping main pristine and always shippable, delivering only one commit at a time, maintaining all the the commit statutes that we build up during the wrapup and ready workflows.
In a 'fast-forward' merge no new commit is created in the process, the main HEAD is simply moved to the existing SHA1. Keeping main pristine and always shippable, delivering only one commit at a time, maintaining all the the commit statutes that we build up during the wrapup and ready workflows.One could ask, why not just reset the issue branch to the squashed commit:
git reset --hard $READY_COMMIT
We actually did that initially, but we soon moved to use the ready branch design:
- We don’t actually know if we’re done yet. The
readyverification flow may fail. In which case I’t will not merge tomainand we need to resume work on the issue. In this case, developers found it more natural to continue work on the original issue branch rather than the kinda arbitrary squashed ready branch. -
The
readyverification flow is different than the one we use on the development branch and it’s different than then one that runs whenmainis updated. It’s easy and convenient to trigger when you have a dedicated branch. Thereadyworkflow triggers like this:on: push: branches: - 'ready/*'
A GitHub Pull request don’t support our principles and How We Work
👎 As discussed intensely in the GitHub discussions referenced above. None of the thee possible merge strategies on PR’s are capable of creating a fast-forward merge onto main. This is basic Configuration Management gospel! We can’t live without it.
👎 Pull Request in general violates our use of issues. PR’s will make annotations on the arbitrary parallel shadow issue, the PR itself. But we want to record annotations and work logs on the issues themselves, to compile a worklog that is easy to read.
👎 Pull Request notoriously creates manual verification tasks; developers are supposed to review code and approve it (mura). Which creates wait states and task switching (muri). It’s just waste in the value stream. Plain and simple.
The DORA metrics
As briefly mentioned above, In relation to the specific DORA metrics — using this flow , we manged to achieve:
- Change Lead Time (CLT) falls within a span between 1 hour and 2 days with only very few outliers counted in days. More than 80% of all issues cluster around 2-3 hours.
- Deployment Frequency (DF) is on demand, we keep our deployment manifest updated on all commits and all SemVer labels and we automatically deploy to both our stage cloud environment (anything that hits
main) and to the cloud QA environment (SemVer release candidates) where we run User Acceptance Tests with end-users. A release to production is only a matter of promoting the SemVer release candidate labels — that will update the deployment manifest and then run a manual (manual for security reasons) trigger of the deployment. - Change Failure Rate (CFR) and Rework Rates (RR) are well below 20%, even with our fully automated hands-off, no-peer-review process. That may seem high to some, but note that it include RR, which isn’t actual failures. And as argued well in the ‘24 report from DORA: “Throughput beats Stability”. So in combination of a low Change Lead Time, A Deployment Frequency on demand and Failed Deployment Recovery Time in check, optimizing further in this field would neither increase the overall quality nor be significantly measurable in the Value Stream.
- Failed Deployment Recovery Time (FDLT) - This is equal to the Change Lead Time, if we chose to roll-forward — and minutes, if we chose to roll back.
Please — let me help you!
We believe that at our devotion to Kanban task management and the fully automated process which verifies quality at the source, as opposed to gluing it on later, is the foundation of what I personally like to refer to as Lean Software Development or Software as a Factory taking the time to take those S.M.E.D3 challenges serious. Continuously optimizing the workflow to improve the Developer Experience.
If you would like a demonstration of the tools we developed over time to support this flow in GitHub (they are all open source), or if you’d like to spark a discussion about some of these principles in your team – or perhaps with the executive level of your organization. If you’re curious on how dramatically simple kanban really is, and just how well suited it is for a DevOps mindset: “You Build It – You Run It”. Or experience how motivating it is for the developers to see the DORA metrics slowly but surely move in you favor.
Then I would love to come by and inspire you. It’s free, I won’t charge you a dime. My mission is to spread the gospel about Lean Software Devolvement and Software as a Factory and hopefully to build a community around the tools that we’ve developed.
Throw some feed-back, Chat me up, Connect to me!
-
Git does have a command
git request-pullBut it’s not what we’re looking for, It’s really (nothing more than) a reporting and email-template generating tool. It kinda summaries the todo-list that the maintainer will go through and it collects the info needed. So it might be helpful, but it doesn’t actually provide any tool support; it doesn’t fetch or merge anything. ↩ -
A Blast from the past: Here’s a news updated from 2005 on the controversy between the Linux Community and the makers of BitKeeper. ↩
-
Toyota’s SMED (Single-Minute Exchange of Die) principle is a lean manufacturing methodology designed to drastically reduce the time it takes to complete equipment changeovers or production setups. Due to the extremely high (positive) impact on the outcome, it’s considered justified even if the development of that effect may assume quite an extensive effort. ↩




Comments